这篇文章将讲述protocl buffer如何对消息进行编码形成要传输的二进制数据。虽然这对我们使用grpc没有任何影响,但是了解其编码原理,可以让我们更了解我们的数据编码后的大小。
一个简单的消息
先看一个最简单的消息定义:
message Test1 {
optional int32 a = 1;
}
假设我们在应用中创建了一个Test1消息,并将其值设为150.
那么,它对应的二进制数据为: 08 96 01
这是什么鬼?别急:
Base 128 Varints
要了解上面消息的编码方式,需要先了解”Base 128 Varints”.这是一种对整数进行序列化的编码算法,对于较小的整数尤其有效,编码整数不是使用固定的4字节或多字节而是可以使用1~多个字节。
varint中每个字节的最高位有特殊含义(msb),1代表后面还有更多字节,否则表示已经结束。多字节的有效数据按小字节序存储。
所以,1的varint编码为0000 0001,只需要一个字节。
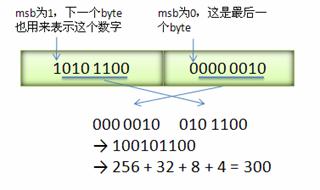
300的varint编码为1010 1100 0000 0010
按照varint编码原则,去掉msb得到010 1100 000 0010
按照小字节序得到 100101100 = 300
Message Struct
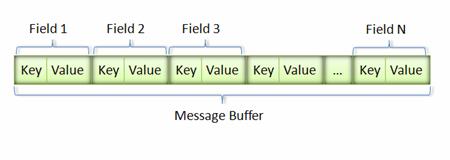
通过前面学习写proto文件,我们知道protocol buffer消息是k-v值。编码后的二进制消息使用proto定义的数字作为key. 至于k值的名称和类型需要解码时使用proto文件中的定义来决定。
当编码时,一个接一个的k-v对组成二进制序列。
当解码时,protcol buffer的解析器实现需要能够跳过不识别的k,这样可以在消息中添加新字段,而不影响老的程序使用。为了达到这个目的,二进制序列中”key”含有2个值---.proto文件中定义的key和值的类型(wire_type)(类型提供了足够的信息来获取后面值的长度)。
protocol buffer中wire_type有以下几种类型:
Type
Meaning
Used For
0
Varint
int32,int64,uint32,uint64,sint32,sint64,bool,enum
1
64-bit
fixed64,sfixed64,double
2
Length-delimited
string,bytes,embbeded message,packed repeated fields
3
Start group
groups(deprected)
4
End group
groups(deprected)
5
32-bit
fixed32,sfixed32,float
key在消息中使用varint编码,(filed_number << 3 wire_type),后3位代表wire_type.
还使用上面的例子,则key编码为:000 1000.
最后3位表示值类型为Varint. key=1(field number)
结合上面varint编码的知识,我们知道96 01 = 150
更多的类型
signed integers
通过上面的学习我们可以知道wire_type 0使用varints编码。
但是对于sint32,sint64和int32,int64有很大的区别。对于负数,如果使用int32,int64,则varints编码会很大,可能会使用10个字节。为了提高效率,如果你使用sint,则会使用ZigZag编码。
ZigZag编码将signed integers映射到unsigned integers.所以对于绝对值较小的数可以更高效地编码。
对于sint32,value n编码为(n << 1)^(n >> 31)
对于sint64,value n编码为(n << 1) ^ (n >>63)
注意,第2个移位操作是算数移位(n>>31),说明只会剩下符号位。
当值类型为sint32,sint64时,解码时会还原出原始值。
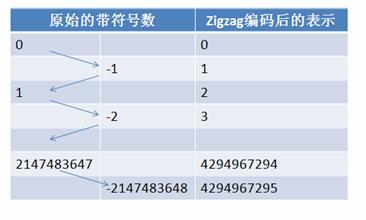
下面是一些数的编码:
Signed Original
Encoded As
0
0
-1
1
1
2
-2
3
2147483647
4294967294
-2147483648
42949672945
Non-varint numbers
double,fixed64有wire_type=1,后面有64bit数据; float,fixed32有wire_type=5,后面有32bit数据。数据都是小字节序。
Strings
“testing”的编码为:12 07 74 65 73 74 69 6e 67
通过前面的介绍,我们知道0x12表明key=2,type=2. 0x07是字符串长度。
Embedded Messages
下面是一个含有嵌入消息的message:
message Test3 {
optional Test1 c = 3;
}
它的编码是:1a 03 08 96 01
0x1a:表明类型为2,key=3.
03:长度.
08 96 01:见前面对150的分析。
Optional And Repeated Elements
对于proto2中定义的repeated元素(没有[packed=true]选项),编码形成的二进制消息中会有相同Key的0个或多个元素.这些repeated元素不一定在消息中连续,可能与其他元素交叉.这些元素的顺序在解码时保证.
proto3对repeated元素默认使用[packed=true]选项.
对于proto3中任何的non-repeated元素和proto2中的optional元素,编码后的消息里可能不包含其k-v数据.
通常情况下,对于non-repeated元素消息中不应该出现多于一个的k-v实例.但是解析器最好能处理这种情况.
对于numeric和strings类型,如果出现多次,应该取最后的值.
对于embedded message,对多个实例进行merge,就像调用Message::MergeForm方法那样
单数标量元素覆盖前面元素;复合元素进行merge;
repeated元素连接在一起。这些规则的结果是:你处理2个消息的连接和分别处理2个消息再连接的结果完全一样。
就像下面的代码:
MyMessage message;
message.ParseFromString(str1+str2)
等价于下面的代码:
MyMessage message,message2;
message.ParseFromString(str1);
message2.ParseFromString(str2);
message.MergeFrom(message2)
这种特性在某些情况下可能有用,因为它允许你合并2个消息,即使你不知道消息的类型。
Packed repeated fields
version 2.1.0引入了packed repeated fields,在proto2中需要使用[packed=true]选项。在proto3中,对于标量numeric类型,这个选项是默认的.不包值的packed repeated fields在生成的消息中为空,对于多个值,会生成一个k-v对,wire_type=2.值的生成规则和前面介绍的一样,只不过少了前面的k.
比如,对于下面的消息:
message Test4 {
repeated int32 d = 4 [packed=true];
}
假设现在有消息Test4,你设置了3,270,86942这3个值。那么编码后的消息如下:
22 //key (filed number 4, wire type 2)
06 // payload size (6 bytes)
03 //first element(varint 3)
8E 02 //second element(varint 270)
9E A7 05 //third element(varint 86942)
只有简单的numeric类型(使用varint编码的32bit,64bit类型)可以使用repeated packed=true选项.
需要注意的是,尽管没有理由使用多个key-value对来编码repeated fields,
但是编码器应该能够分开的接受多个值并将它们连接在一起。
对于解码器应该能够处理repeated fields使用了packed=true而实际没有这样编码(使用单个key)的数据,反之亦然。这样能够对新添加了packed=true的新消息的情况做到兼容。
Field order
Field number在.proto文件中的顺序可以任意,这对编码序列化没有任何影响。
当对一个消息进行序列化时,不用保证field在消息中的顺序和未知field的写入。序列化field的顺序是一个实现细节,这个特定的实现在将来可能会改变。也就是说,protocol buffer的解码器应该能够处理任意顺序。
启示
- 不要假设序列化输出的字节序列是稳定的
- 默认情况下,对于同一个protocol buffer消息实例重复调用序列化方法的结果可能会不同
- 下面的检查对于protocol buffer消息实例foo可能并不成立
- foo.SerializeAsString() == foo.SerializeAsString()
- Hash( foo.SerializeAsString()) == Hash(foo.SerializeAsString() )
- CRC( foo.SerializeAsString()) == CRC(foo.SerializeAsString() )
- FingerPrint( foo.SerializeAsString()) ==
FingerPrint (foo.SerializeAsString() )
- 对于逻辑上相同的2个消息foo,bar,序列化后的字节序列可能不同。下面是一些可能的场景:
- bar是由一个老的server序列化产生的,将一些字段识别为不认识的字段。
- bar是被不同编程语言实现的序列化器以不同顺序编码的。
- bar 中有字段的编码方式是不确定的