简介
在上一篇文章里,我介绍了OS调度方面的相关内容,我认为这些内容对理解Go调度器的语义很重要。本篇文章,我将从语义层面会介绍GO调度器是如何工作的,将会重点关注G调度器的高层行为。Go调度器是一个复杂的系统,小的细节是不重要的。重要的是我们要有一个对Go调度器如何工作和其调度行为的好的认知模型。这些有助于我们做出工程上的决策。
启动你的程序
当你的Go程序开始运行,会分配一个逻辑处理器(P)用于执行特定主机上的虚拟代码。如果你有一个支持每个物理核上跑多线程的处理器(超线程技术),每个硬件线程在你的Go程序里都是一个虚拟核。为了更好地理解这些内容,来看一下我的MacBook Pro上的系统报告:

可以看到一个处理器上有4个物理核心,这个报告看不到每个物理核上的硬件线程。i7处理器支持超线程技术,每个物理核上有2个硬件线程。这说明Go程序有8个可用的虚拟核用于并行地执行OS线程。
看下面的程序:
1 | package main |
在我的机器上运行上面的程序,会输出8.任何一个运行在我机器上的Go程序都会有8个虚拟核P.
每个P被分配一个OS线程(“M”).M代表machine.这个线程仍然被OS管理,仍然由OS负责将其放到某个核上执行,如上篇文章所讲的那样。这意味着,当我运行Go程序时,有8个线程可用于执行我的任务,每个都与一个P关联。
每个GO程序都会分配一个初始的Goroutine(“G”),代表了GO程序的执行路径。一上Goroutine本质上是一个Coroutine,但是是Go语言,因此将”C”替换为”G”.你可以将Goroutines看作是app级别的线程,它们和OS线程有很多相似点。OS线程会在一个cpu核上进行上下文切换,Goroutines会在M上进行上下文切换。
最后一个难点是运行队列。Go调度器有2种不同的运行队列:全局运行队列(GRQ)和本地运行队列 (LRQ).每个P都有一个本地运行队列用于管理分配给它的Goroutines。这些Goroutines轮流在分配给P的M上进行上下文切换。GRQ用于还没有分配P的Goroutines.有一个专门的程序用于将Goroutines从GRQ移动到LRQ。
下图描述了这些组件之间的关系:
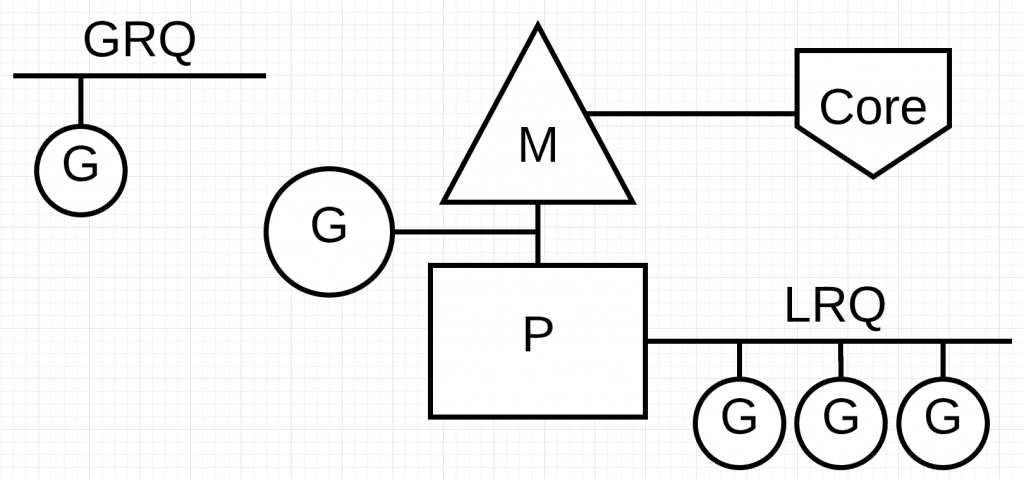
协作调度器
如上一篇文章中所讨论的,OS调度器是可抢占的。这在本质上意味着在任何时刻,你无法预测调度器会做什么。内核做的决定和事件是不确定的。运行在OS之上的应用程序无法控制内核调度器,除非使用原子指令和锁这些同步原语。
Go调度器是Go运行时的一部分,Go运行时与你的程序构建在一直。这意味着Go调度器运行在用户态。现在的Go调度器实现是不可抢占的,而是协作型的调度器。协作调度器意味着调度器需要定义良好的用户空间事件,这些事件需要在安全的时间点触发调度决策。
Go的协作型调度器实现的十分聪明,因为它看起来就像是可抢占的。你无法预测Go调度器将会如何调度。这是因为调度决策没有交给开发者,而是交给了Go的运行时。将Go调度器看成是可抢占的十分重要,因为它是不确定的,这一点并不难理解。
Goroutine状态
和线程类似,Goroutines也有3个状态。
Goroutine的3种状态包括:Waiting, Runnable 或者_Executing_.
Waiting: 意味着Goroutine因为要等待一些事件而停止。可能包括等待系统调用,同步调用(原子操作和锁操作)。这些类型的延迟是性能差的根源。
Runnable: 这意味着Goroutine希望在M上获取运行时间来执行指令。如果同时有很多Goroutines,每个Goroutine需要等待更长的时间,同样地,每个Goroutine获得时间就会减少。这种调度延迟也会造成性能较差。
Executing: 这意味着Goroutine已经在M上执行指令。这是每个人都希望的状态。
上下文切换
Go调度器需要定义良好的用户空间事件来在安全的时机进行上下文切勿。这些事件和安全的时机以函数调用的方式提供。函数调用对Go调度器的健康至关重要。现在(Go1.11和以前的版本中),如果你运行紧凑地循环代码而不进行这些函数调用,那么调度和垃圾回收就会产生延迟。在合适的时机调用这些函数是十分重要的。
注意: 1.12版本已经接受了go调度器实现抢占的建议,这样就能够抢占长时间的循环.
有4类事件会使go调度器进行调度决策。这并不意味着一定会发生新的调度,而是给调度器提供了调度的机会.
- 使用go关键字
- 垃圾回收
- 系统调用
- 同步和编排
使用go关键字
go关键字能够创建Goroutines. 一旦创建了新的Goroutine,调度器就有机会进行调度决策.
垃圾回收
由于GC使用自己的Goroutines运行,这些gorutines需要在M上获得执行时间.这会对调度产生影响。幸好,调度器非常聪明,它对Goroutine正在进行的工作十分了解能够做出聪明的决定。一个例子是:在GC期间,调度器调度那些不需要访问堆的goroutine,而将那些访问堆的goroutine切换出去。当运行GC时,会做出许多调度决策。
系统调用
如果一个Goroutine进行了一个会阻塞M的系统调用,有些时候调度器能够将其切出M并调度一个新的Goroutine。但是,有时候需要一个新的M来运行Goroutines并将其加入P的队列之中,这是如何工作的细节下一节将会详细介绍.
同步和编排
原子操作,锁,channel操作会引起Goroutine阻塞,调度器可以切换一个新Goroutine运行。当Goroutine双可以继续运行时,会被重新放入运行队列并最终切换回M运行。
异步系统调用
如果你的OS支持异步系统调用,比如网络poller,它可以更高效地处理系统调用。这是通过kqueue(MacOS),epoll(Linux),iocp(Windows)实现的。
现今的许多OS都支持异步的处理网络相关的系统调用。这也是network poller名字的由来,因为它最初产生是为了处理网络操作。通过使用network poller相关的系统调用,调度器能够防止Goroutines阻塞当前M。
这有助于M继续执行P的LRQ上的其它Goroutines,而不需要创建新的M。这能够降低OS的调度负荷。
下面的图很好的说明了上述情况:
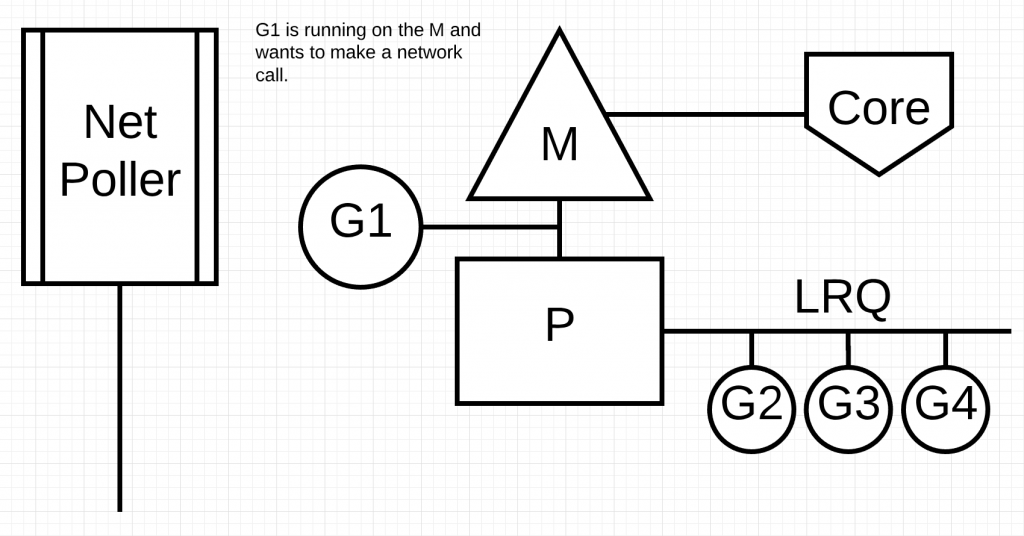
上图中,G1正在M上运行,它想进行一次网络调用。
下图中,G1加入net poller中进行异步调用。M这时可以执行LRQ的另一个G2。当异步调用完成时,G1又放入P的LRQ之中。这是一个巨大的成功,因为不需要创建额外的M。net poller有专门的OS线程处理而且十分高效。

同步系统调用
当Goroutine进行不能进行异步处理的系统调用时会发生什么?这时,进行系统调用的Goroutine将会阻塞M,不幸地是没有办法阻止这种情况的发生。一种可以进行异步调用的系统调用是文件操作。如果你在使用CGO,那么有可能会因调用其它C函数而造成M阻塞。
注意: Windows没有提供异步读写文件的能力.当在Windows上运行时,可以net poller.
下面我们就来看一看如果进行同步调用(比如文件I/O)造成M阻塞的情况。
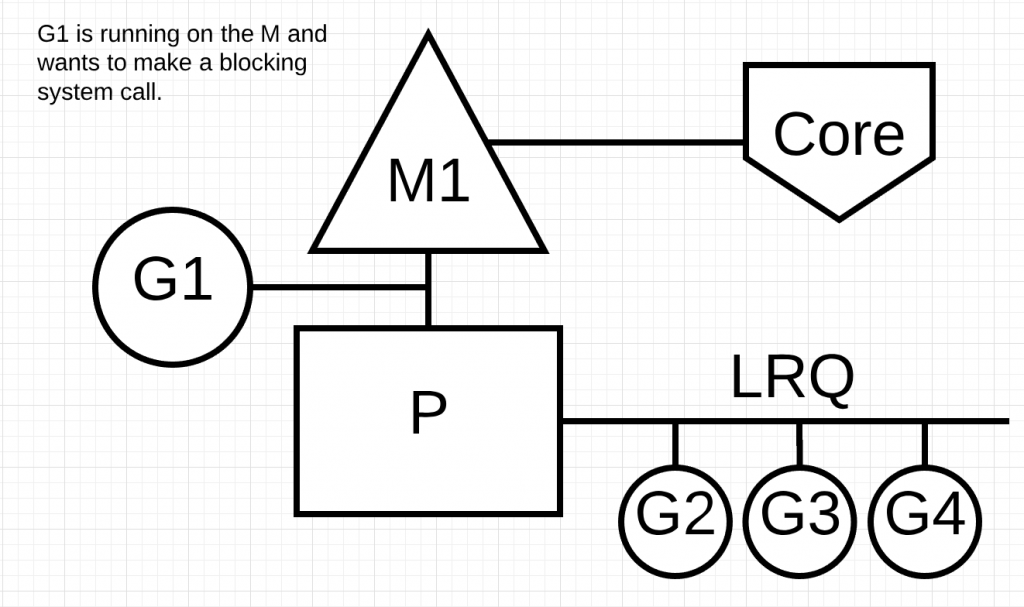
上图中G1将要进行同步调用。

在上图中,调用器将识别出G1将会造成M阻塞。这时,调度器将M1与P分离,G1仍然关联在M1上。然后调度器使用一个新的M2为P服务。G2被从P的LRQ中选出并切换到M2上运行。如果因为之前类似的情况已经有一个M存在,上面这种切换会更快,因为不需要新创建一个M.
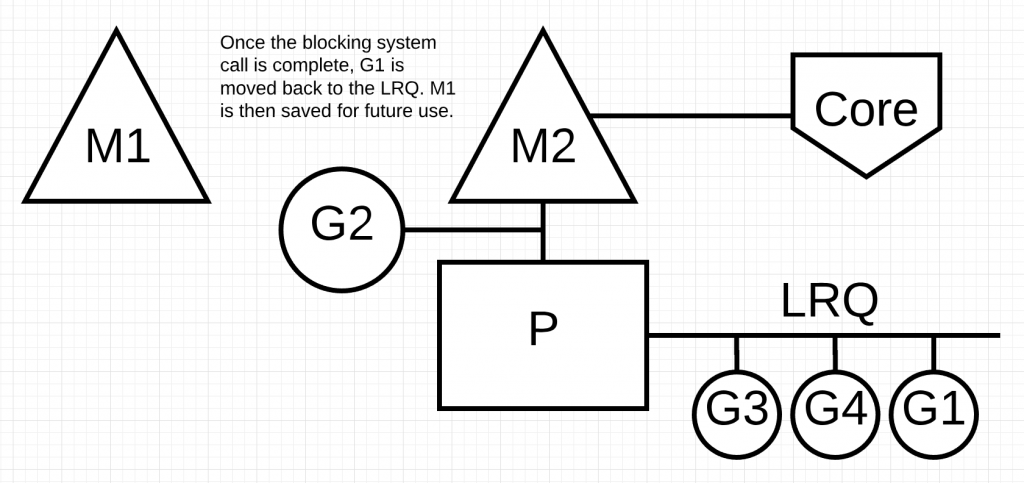
如下图所示,G1完成了系统调用.这时,G1被移回P的LRQ继续由P服务。M1继续在一旁保留着用于将来再次发生类似情况时使用.
工作窃取
在另一方面,调度器还是一个工作窃取型的调度器。这能够在某些情况下保持调度的高效。比如,上面讲的M进入等待状态时,OS将会将M切换出当前核。这意味着即使还有可以运行的Goroutine,P也不能够进行任何工作,直到M切换回某个核。工作窃取能够在P之间平衡Goroutines,这样工作能够有较好的分派进而更高效的完成。
我们通过下面的图来看一下:
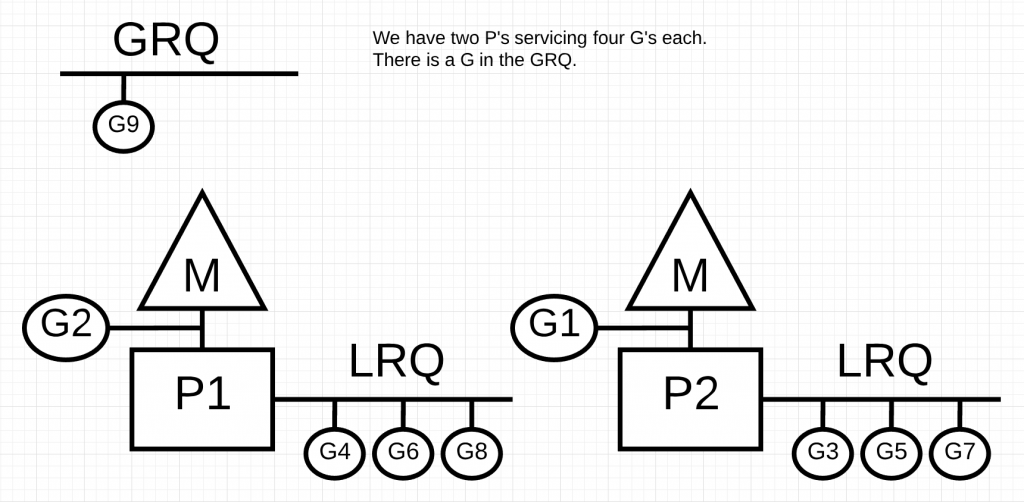
在上图中,我们有一个多线程程序,有2个P,每个P为4个Goroutines服务。还有一个GRQ在执行一个Groutine,如果有一个P工作较快,那么会发生什么?
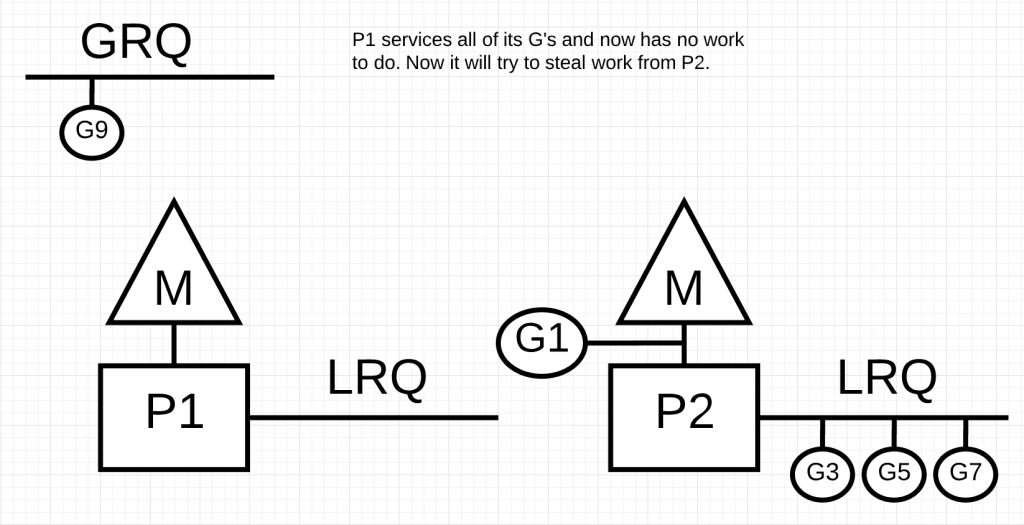
在上图中,P1已经没有可运行的Goroutines了,而P2和GRQ上还有。这时,P1需要进行工作窃取。工作窃取的原则如下:
1 | runtime.schedule() { |
基于上述原则,P1将会从P2中窃取G,并窃取一半的可运行G.如下图所示:
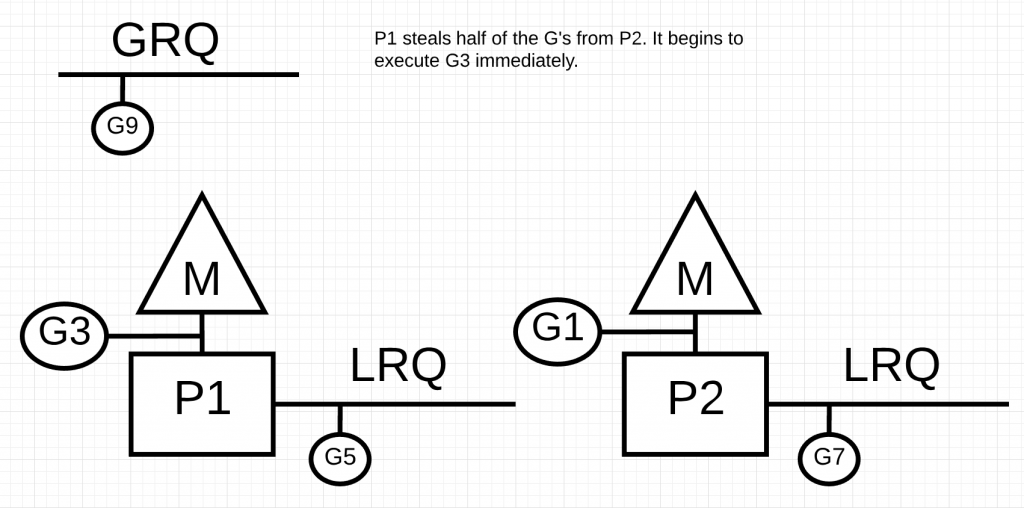
如果这时P2工作完成,P1的LRQ上也没有G了,那么P2会怎么做?
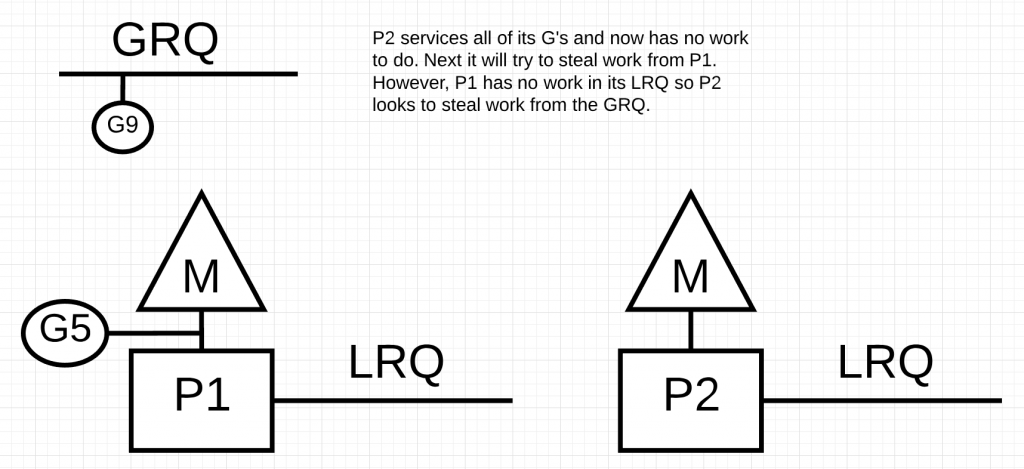
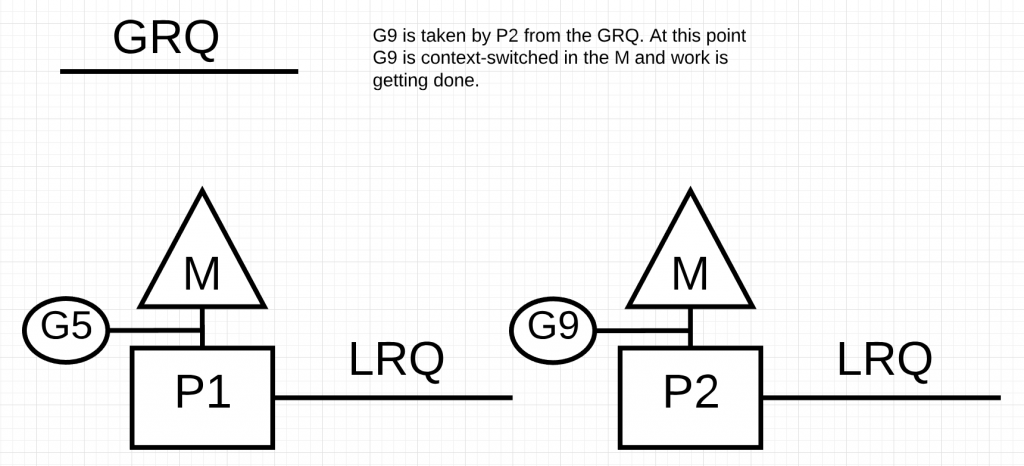
如上图所示,P2会从GRQ上取走G9并执行。可以看出,窃取工作能够使M始终处于工作状态。
实际的例子
通过上面介绍的机制和语义,我想向你展示这些是如何作用在一起来使GO调度器执行更多的任务。假设现在有一个用C写的多线程的程序,它管理着2个OS线程并来回传递消息。
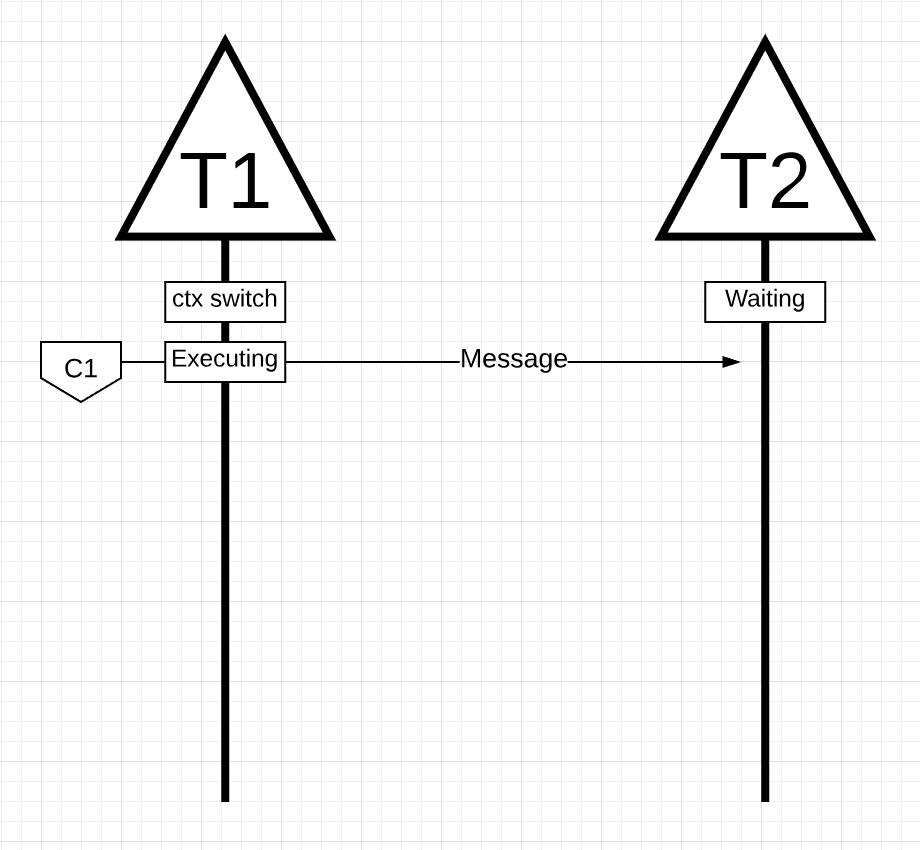
如上图所示,线程T1在核C1上运行并发送消息给T2.
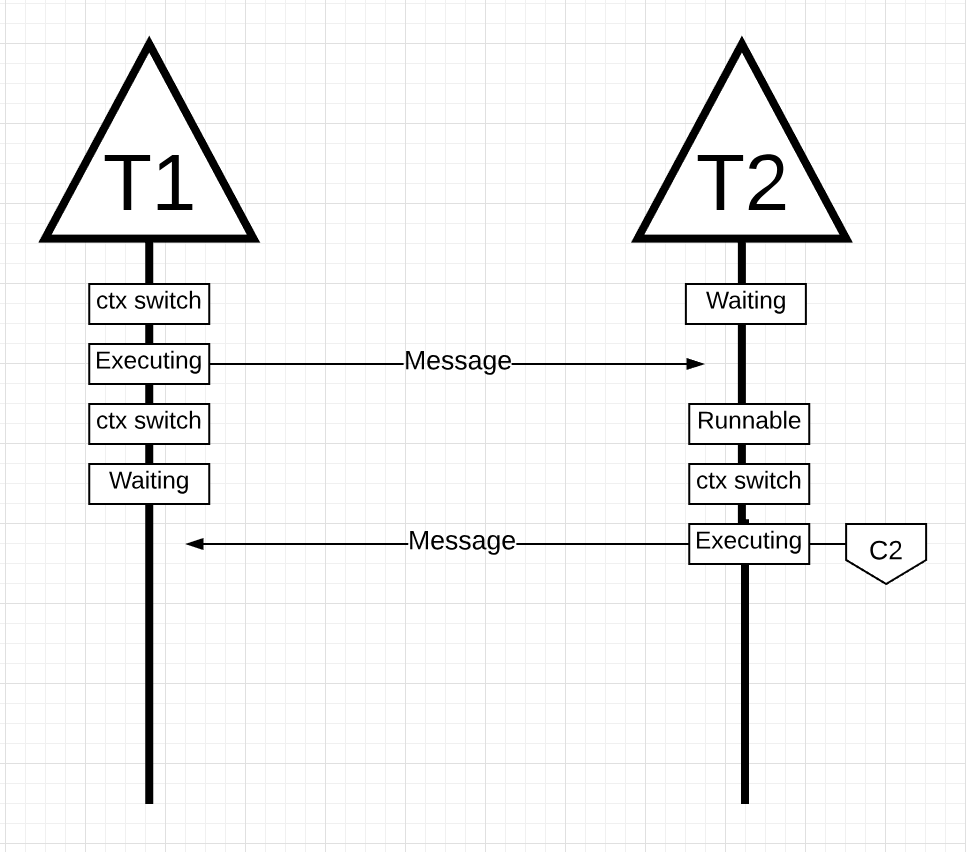
当T1发送完消息以后,它需要等待T2的回应。这会使T1从核C1上切出并进入等待状态。一旦T2接收到消息通知,它进入可运行状态。现在OS执行一次上下文切换并在核C2上执行T2。接下来,T2处理完消息并向T1返回一个消息.
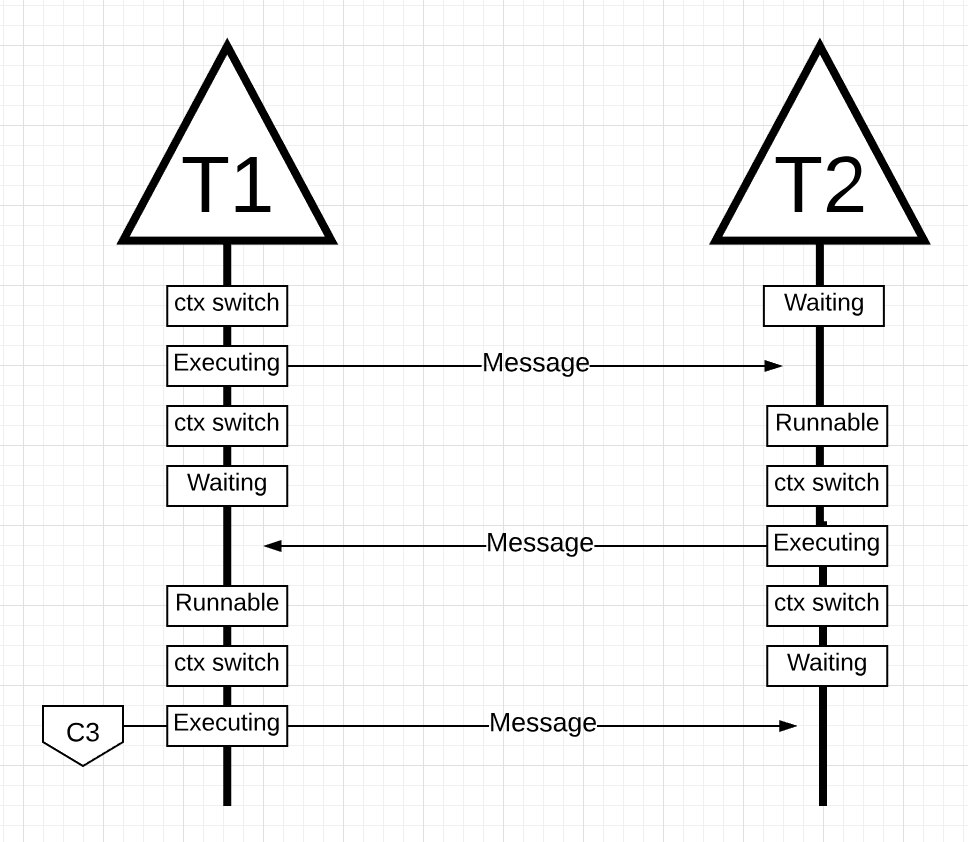
当T1接收到消息后,会再次进行上下文切换。现在T2进入等待状态,T1从等待状态进入可运行状态并最终执行,T1继续处理消息并发送新的消息.
所有这些上下文切换和状态变化需要时间,这限制了任务快速的完成。每次上下文切换都可能有约1000ns的延迟,通常硬件每ns执行12条指令,这就造成在上下文切换期间浪费了12K指令的执行。再加上这些线程绑定到不同的核上,缓存行失效问题也会造成额外的延迟。
让我们再来看看使用Goroutines的Go调度器如何处理这个例子:
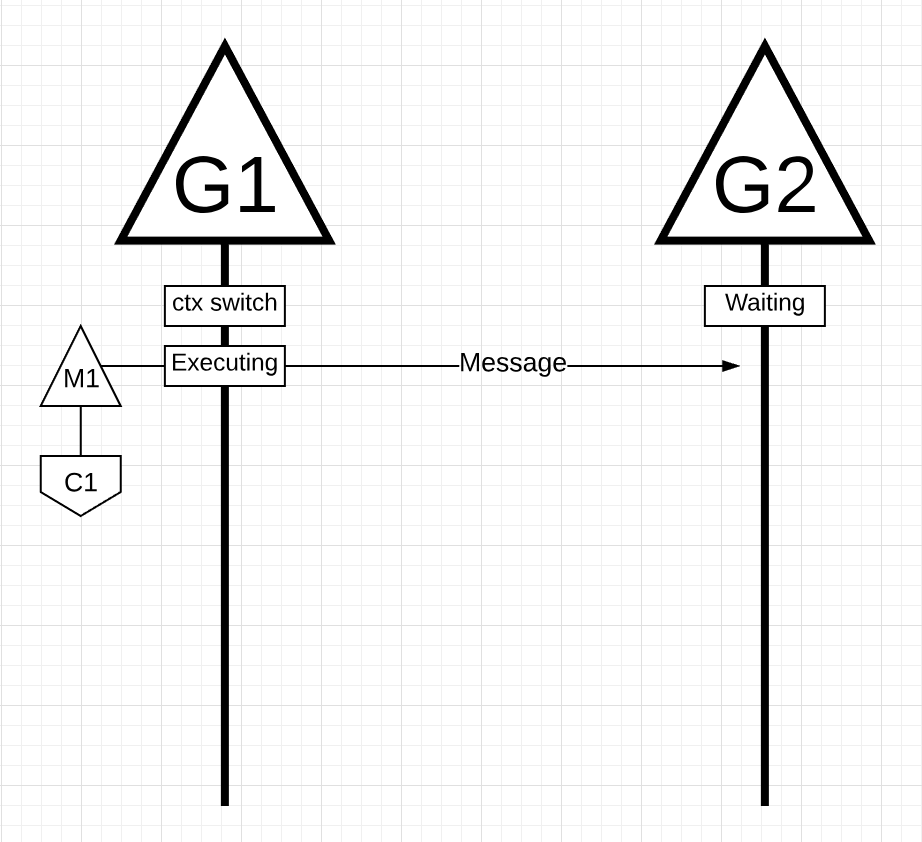
如上图所示,有2个Goroutines用来相互发送消息.G1在M1上运行,发生在核C1上。
G1发送消息给G2.
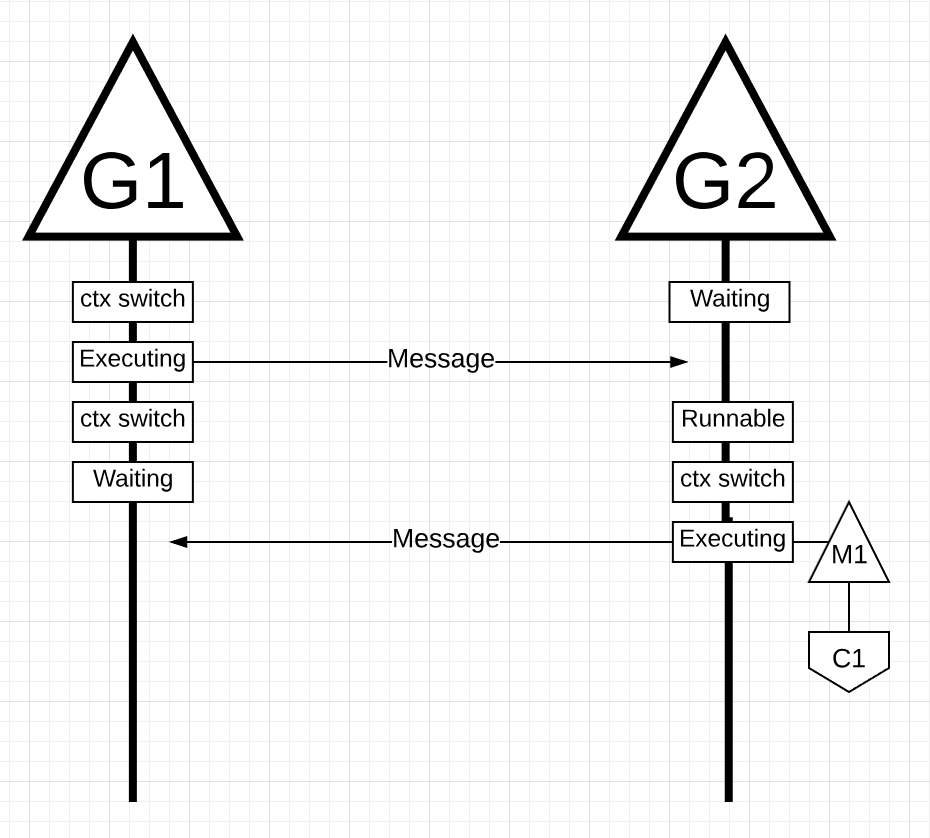
G1发送完消息后,等待回应。G1从M1上切出并进入等待状态。G2接收到消息通知并进入可运行状态。这时Go调度器执行一次上下文切换在M1上执行G2,同样运行在核C1上。接下来,G2处理消息并向G1返回响应.
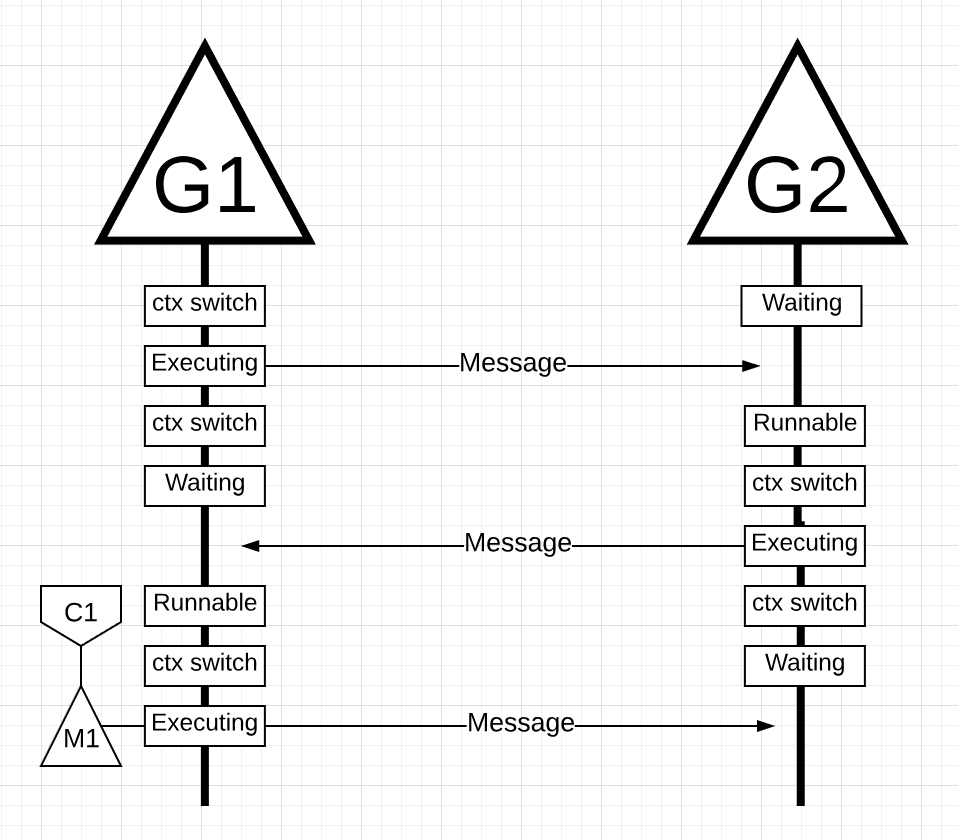
G1接收到G2的响应后,G2切出并进入等待状态。G1最终执行起来并发送响应.
所有这些事情从表面上看和多线程里没有任何不同。Goroutines上同样存在上下文切换和状态变化问题。但是,使用线程和Goroutines有一个主要的不同可能第一眼不易察觉。
使用Goroutines的场景,用一个OS线程和CPU核就处理了所有的事情。这就意味着,从OS的角度看,OS线程从来没有进入过等待状态。而且不止一次的,我们在上下文切换期间(Go调度器切换代价小的多)没有丢失指令执行的机会。
本质上,Go在OS层面上将I/O阻塞型任务转变为CPU密集型任务。由于这些上下文切换都发生在用户态,因此我们没有像使用线程时那样在每次上下文切换中损失12k指令(平均)。在Go里,同样的上下文切换花费约200ns或者说2.4指令。Go调度器还有助于提升缓存命中和NUMA.这也是为什么我们不需要大于虚拟核数量的线程。在Go里,同样的时间可能完成更多的任务,这是因为Go调度器尝试减少线程数量,并让每个线程干更多的活,这能够减少OS和硬件的负担。
总结
Go调度器在设计时考虑到了OS和硬件的工作方式,这很令人惊奇。
将I/O阻塞型工作转换为CPU密集型工作的能力使我们在利用多CPU上取得了巨大的胜利。这也是我们不需要大于虚拟CPU数量的线程个数的原因。你有理由相信你的所有工作(无论CPU密集还是IO密集)可以在每个VC(虚拟核)一个线程的情况下完成。这对于网络和其它不需要阻塞线程的系统调用的应用来说是有可能的。
作为一个开发者,你还是需要了解你的程序需要处理的工作类型。你不能创建无限多的Goroutines并期待高性能。少即是多仍然适用,但是了解了Go调度器的这些语义,你可以做出更好的工程决策。
在下一篇文章里,我将以保守的方式来展示如何利用并发性来获得更好的性能,同时平衡你可能向代码里添加进的复杂性。