golang程序启动流程详解
环境
go1.16.5 linux/amd64
用例
1 | package main |
编译
-gcflags “-N -l”: 关闭优化和内联,方便调试跟踪
1 | go build -gcflags "-N -l" -o hello hello.go |
gdb跟踪执行流程
1 | gdb hello |
预备知识:
1. GMP调度模型
- Golang的调度器模型是”GMP”模型,P作为逻辑cpu的抽象,解决了竞争全局队列等问题.
- M是操作系统线程,M必须关联到某个P上,从P上获取工作goroutine
- 一个P可能有多个M,当某个M阻塞时.
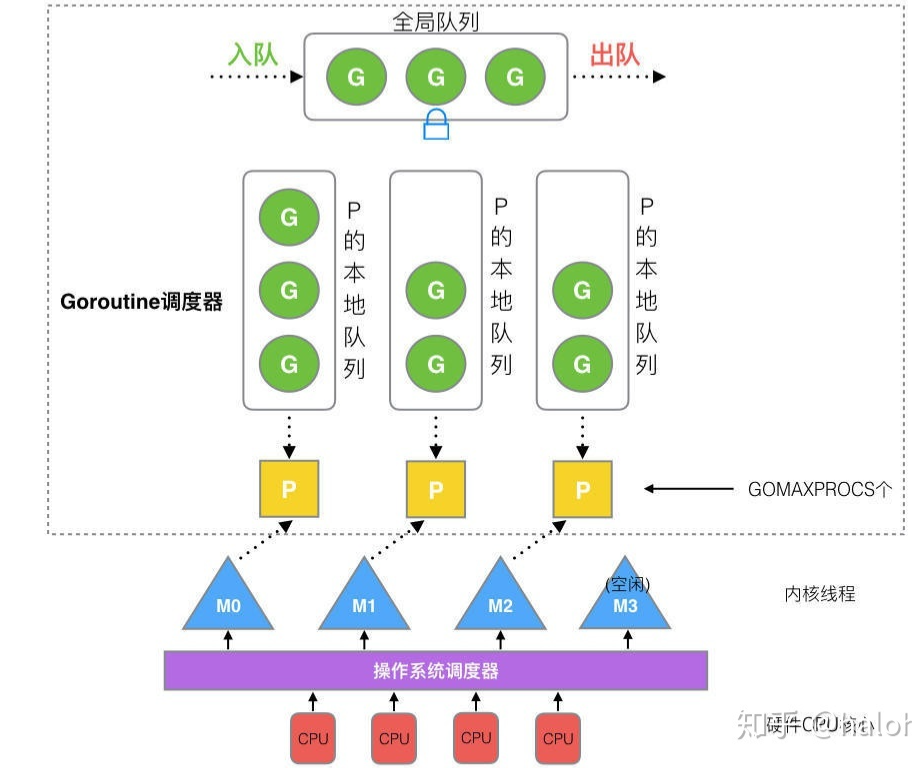
2. runtime/proc.go中定义了一些重要的全局符号,下面分析启动流程会涉及这些符号:
1 | var ( |
- g0: 主线程上的第一个协程g0, g0拥有这个线程的系统栈,这个栈很大.g0还有创建新协程的职责,当我们调用go func创建新协程都会在g0的栈上执行.
- m0: 第一个工作线程,主线程
- mcache0: m0的cache
3. tls线程私有存储
每个线程的私有存储空间,golang主要用其来设置每个m当前正在运行的goroutine,这样可以快速获取到当前上下文的goroutine. 类似于linux内核中的current宏.
4. sched全局结构
golang使用一个全局schedt结构来控制全局调度(runtime2.go),里面主要的信息如全局运行队列,所有m,所有p的状态信息,系统监控sysmon等
1 | var ( |
程序入口函数:
- 为g0分配栈空间
1 | runtime.asm_amd64.s:89 |
- 获取cpu相关信息
1 | // find out information about the processor we're on |
- 初始化tls,设置m->g0, g0->m,初始化sched信息
1 | MOVQ _cgo_init(SB), AX // 查看是否有_cgo_init,如果有则需要调用,我们的例子中没有_cgo_init |
1 | type m struct { |
sched初始化
sched内容比较多,我们详细来看一下:
1 | _g_ := getg() // 获取当前的goroutine, 之前已经保存在tls中了,getg就是从tls中获取 |
sched初始化就完成了,主要就是一些全局信息,包括内存,栈缓存,P的个数,gc等.
再回到汇编:
- 设置主协程入口函数runtime.mainPC,调用newproc创建主协程
1 | CALL runtime·schedinit(SB) //600 |
newproc:
- 创建主协程并将其放到p的本地队列中,systemstack函数表示在系统栈上执行goroutine的创建操作
1 | argp := add(unsafe.Pointer(&fn), sys.PtrSize) // 获取argp |
systemstack
1 | TEXT runtime·systemstack(SB), NOSPLIT, $0-8 |
1 | systemstack(func() { |
newproc1:
newproc1的作用是为执行函数分配新的goroutine
1 | func newproc1(fn *funcval, argp unsafe.Pointer, narg int32, callergp *g, callerpc uintptr) *g { |
创建好新的goroutine后,继续:
1 | systemstack(func() { |
新goroutine创建完成,再启动一个m,这个m目前是主线程,即m0
1 | CALL runtime·newproc(SB) |
初始化m0,设置线程id
1 | func minit() { |
- m0,g0都初始化完成后就开始执行主协程,这时通过汇编代码gogo执行主协程
1 | TEXT runtime·gogo(SB), NOSPLIT, $16-8 |
- 执行主协程入口proc.go: main
主协程会启动sysmon线程进行监控,然后执行package main里我们实现的main函数
1 | ... |
上面就是一个go程序的启动流程,总结一下:

我们再来分析一下调用go func创建协程的流程
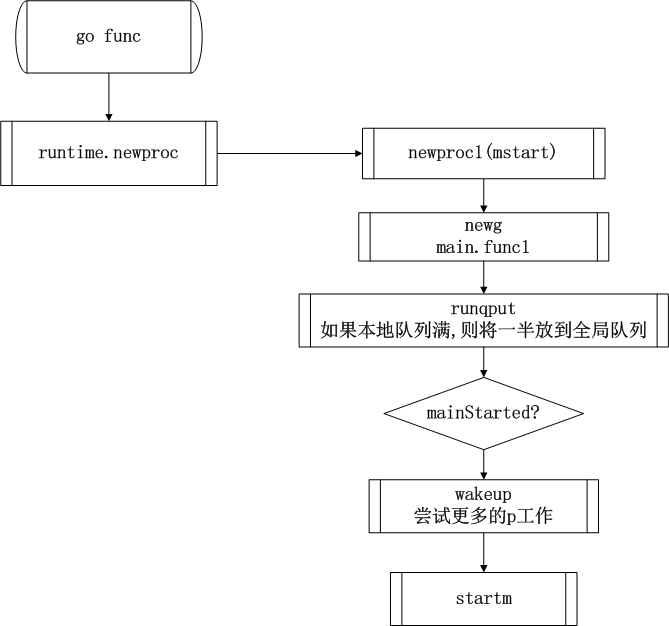
- go func关键字会被编译器转换为runtime.newproc调用创建新协程
- 新协程加入当前p的本地队列
- 如果本地队列已满,则批量将一半的goroutine放入全局队列
- 之前主协程已经设置了mainStarted标志,因此会调用wakeup尝试唤醒更多空闲的p来工作